My apologies, it is this file /etc/ssh/ssh_config
Please share the output of pbsnodes -av and pbsnodes -aSjv
Hi Adarsh,
StrcyHostKeyCheck was anyway commented in ssh_config. I uncommented and made it no. However, it didn’t make any difference.
Here are the output of the commands you asked for - https://ufile.io/f/remyu
Thank you Vinay, all looks good to me.
- Please try this and does this work:
**As vinay on pb0**
ssh pb1 hostname
ssh pb2 hostname
**As vinay on pb1**
ssh pb0 hostname
ssh pb2 hostname
**As vina on pb2**
ssh pb1 hostname
ssh pb0 hostname
- Please unassign the queue mapping on the nodes, it seems pb1 and pb2 are mapped to queue “all”, not recommended node to queue mapping ( this is also not the reason for your issue)
#as root user
qmgr -c "unset node pb1 queue"
qmgr -c "unset node pb2 queue
"
- Delete the nodes and add them with pb2 first
#as root user
qmgr -c "d n pb1"
qmgr -c "d n pb2"
qmgr -c "c n pb2"
qmgr -c "c n pb1"
- submit the job using qsub submit.sh
Hi Adarsh,
SSH outputs. it works fine. -

Unset nodes from queue -

Deleting and re-adding nodes pb2 first and pb1 second

Now submitting the job, it runs on both -

pb1-

pb2 -

But what changed ? we just deleted and readded nodes in a different order.
And also, I tried one mpi parallel code -
#!/bin/bash
#PBS -N ved
#PBS -q all
#PBS -l select=2:ncpus=4:mpiprocs=4
#PBS -l place=scatter
#PBS -j oe
#PBS -V
#PBS -o log.out
cd $PBS_O_WORKDIR
cat $PBS_NODEFILE > ./pbsnodes
$PROCS1=cat ./pbsnodes|wc -l
mpirun -machinefile $PBS_NODEFILE -np 8 ./1D
/bin/hostname
This also ran fine. What is the meaning of mpiprocs in this. This is a students code, just trying to understand.
Nice ! Very good, there must have been some issue with the DNS / hostname resolution when the nodes were added.
mpiprocs : number of MPI processes per chunk ( in your case with respect to the above MPI job, you a have asked for 2 chunks of select=1:ncpus=4:mpiprocs=4 )
Hi Adarsh,
Understand. So now in our test case as we two nodes with 8 cores each.
I got a query.
now I submitted a job with this -
#PBS -l select=1:ncpus=4:mpiprocs=4
#PBS -l place=pack
And job started on pb2 with 4 core -
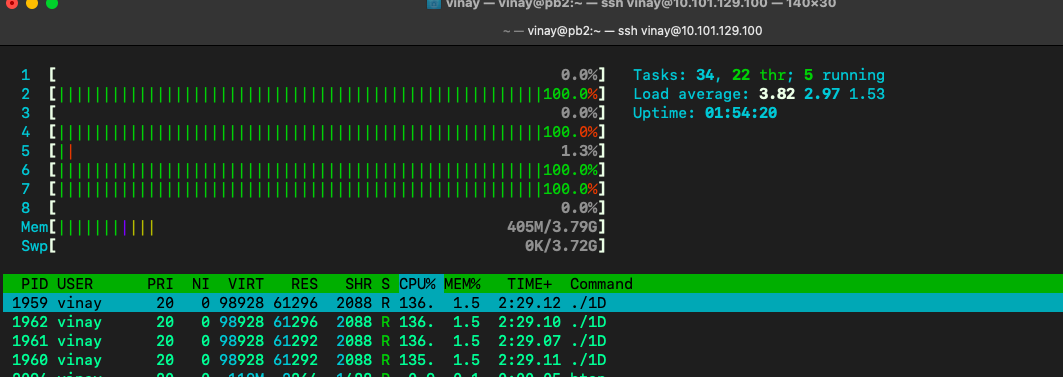
So, in total, we still have 12 core left. 8 from pb1 and 4 from pb2

Suppose a user wants to run a job with 12 core. And let PBS decide how it wants to split.
What should I write -
#PBS -l select=2:ncpus=6:mpiprocs=6
#PBS -l place=free
It stays on Q with above method. and says resources not available. how can I run on the remaining 12.
What I want is, a user should not bother at looking in which node how many cores are there.
If he submits for 12 core, and if 12 core is available in total PBS should distribute it on its own.
Is there a way to check this.
You are asking each chunk to have 6 cores , there is no node free now with 6 cores. There is one node with 8 cores and other node has 4 cores, hence the scheduler keeps the job in the queue. If you specify -l place=free, it does not mean that PBS will automatically adjust amoung available 12 cores with chunk request that has been made. It always depends on how user wants to run their jobs.
The users should not be allowed to look at the nodes or resources ![]() then they will start to game the system by changing their job request to get in their first, it would be the job of the scheduler to do the needful based on resource requests.
then they will start to game the system by changing their job request to get in their first, it would be the job of the scheduler to do the needful based on resource requests.
#PBS -l select=12:ncpus=1:mpiprocs=1
Hi Adarsh,
Understood. Thanks for all the help. I need to create queues as below -
Total nodes - 10 nodes - 16 core - Total 160 cores
In the below priority order
Q1. max - 10 nodes - max cores 160 core - max walltime 30 mins
Q2. 4 nodes - max cores 64 cores - max cores 10 days
Q3. 1 node - 1 core - 10 days
Queue priority -
qmgr -c “set queue Q1 priority=0”
Is this right way. and 0 is the highest priority right ? and it follows as 0,1,2 …
Maximum number of jobs allowed by a user in queue and in run (Below example is the user will be able to submit max 20 jobs out of 10 can be in run state)-
qmgr -c “set queue Q1 max_user_queuable=20”
qmgr -c “set queue Q1 max_user_run=10”
How to set max and default wall-time for a queue.
You are welcome Vinay.
Not correct
If you have 3 queues with priority -1 , 0 , 10
The queue with priority 10 has the highest priority.
Queue priority value can range from -1024 to 1023
with 1023 being the highest priority and -1024 lowest priority
s q QUEUENAME resources_max.walltime=HH:MM:SS
s q QUEUENAME resources_default.walltime=HH:MM:SS
Hi Adarsh,
Also is there a way i can assign maximum cores to a queue
For eg. I have 10 nodes with 16 each. Total 160 cores
I want Q1 to have max cpu=64
Q2 to have max cpu 160
So a user can choose the queue accordingly as per his requirements and submit job.
Will the below command set cpu restriction over a queue
Such for QueueA : 5 CPUs
s q QueueA max_queued_res.ncpus ="[u:PBS_GENERIC=5]"
qmgr : set queue Q1 resources_max.ncpus=64
qmgr: set queue Q1 resources_available.ncpus=64
qmgr : set queue Q2 resources_max.ncpus=160
qmgr: set queue Q1 resources_available.ncpus=160
This means set the maximum number of CPUS for the generic users to 5 on QueueA
Hi Adarsh,
Thanks. Got it. In the 10 nodes we have, 4 nodes have nvidia GPU card.
I read the document and saw there are two ways to do it in PBS.
- Simple GPU Scheduling with Exclusive Node Access - (looks more sensible for our setup)
Document -
Need your views on this. As we don’t have multiple GPU’s on one system, cgroup way is not needed.
Also, after adding GPU as a resource, do you think creating a separate queue and adding those nodes in that queue will be any help or users can submit to the regular queue just asking for the GPU resource.
As there are not many cuda users right now, the nodes CPU can get used, and when a GPU code is submitted the node becomes free and only runs GPU code at that time.
I adding a GPU queue and giving it high priority will also help ?
Sure, only ngpus resources have to be created and used.
You can create a queue for:
1, cpu only nodes
2. gpu only nodes
3. all nodes which includes cpu and gpus
This is to just make sure that cpu only jobs does not take up gpu nodes and gpu requested jobs remain in the queue.
If you have separate queue for gpu nodes, there is no need of setting up priority.
Hi Adarsh,
After creating a queue I am trying to set restriction in below manner -
- Q1 - 64 cores for per user
- Max job in Q1 he can submit 2
- 1 Job can run at a time and one will be in queue
And similar restriction on other Queues.
- qmgr : set queue Q1 max_queued_res.ncpus=[u:PBS_GENERIC=64]
This sets the core restriction for a user on Q1 - qmgr -c "set queue Q1 max_queued=[u:PBS_GENERIC=2]
qmgr -c "set queue Q1 max_run=[u:PBS_GENERIC=1]
This sets user to submit two jobs on Q1 and one can be in run state.
Issue I am facing here is, ncpus restrictions places overall restriction on the Q1.
So if a user submits a 64 core job on Q1 he exhausts his core.
So he can submit two jobs 58 core and 4 core or 32 core two jobs.
What I want to achieve is -
He should be able to submit max 64 core two jobs.
Out of which 1 can be in run and 1 can be in queue.
This should be the same for every user. Queue wise.
Other users should also be able to submit 2 64-cores jobs like the user one and the same restrictions for him too.
Such there will be more queues like Q2 where core restriction will be 32 and jobs can be 3 out of which 2 can be in run state.
How do I achieve this. I tried various combinations, was not able to get the desired result.
Please see the PBS Professional Administrator’s Guide, section 5.15, “Managing Resource Usage”, starting on page AG-290. In particular, sections 5.15.1.1 onward may be helpful.
1 Like
Dear Anne,
Thanks. I adjusted the rules after going thru the document. Thanks again for the help.
Hi Adarsh,
With your help we solved the job submission issue. Which was basically our pbs script problem.
But now a user, submitting the job same way, but his job does not run on more than one node. Same as we reported earlier.
He is trying to submit an openfoam job.
His job it shows us in tracejob and pbsnode -aSj that it is running on two node. One node is of 32 cores. But when we ssh that node and see. Job on only one node is running and the other node is empty. Same user tries to submiit an openmpi job. Works fine as it should.
Not sure why there is different behaviours by pbs for different kind of job
His script sample -
#!/bin/bash
#PBS -q big
#PBS -l select=64:ncpus=1
#PBS -N refined_mach8
#PBS -j oe
cd $PBS_O_WORKDIR
blockMesh
topoSet
splitMeshRegions -cellZones -defaultRegionName fluid -overwrite
decomposePar -allRegions -dict system/decomposeParDict -force
mpiexec -N 64 chtMultiRegionFoam -parallel
reconstructPar -allRegions