I have a machine (machine1) with 96 CPUs. When I submit an abaqus job directly on this machine, the calculation time is about one and a half hours. However, when I submit it to this machine (machine1) through pbs and use the same number of CPUs to calculate the same job, it takes two and a half hours. How can I solve this performance problem?


Please check the below while running without openpbs and with openpbs
- system environment variables
- application environment variable
If you could share the application batch command line used with and without the scheduler.
But,I’m sorry, I don’t know which environment variables I should check,could you give me some hints?
Please share the process of submitting jobs directly on that 96 core host, before doing that type “env” and get the enviorment variable setup and the batch command line used
Please share the script and the process of submitting job through PBS. If you are using a script , add a line “env” to that script , just before calling the batch commandline
I used a machine with 18 CPUs to calculate a job in same situation. The job was completed about half an hour faster when submitted directly or through pbs. The details are as follows:

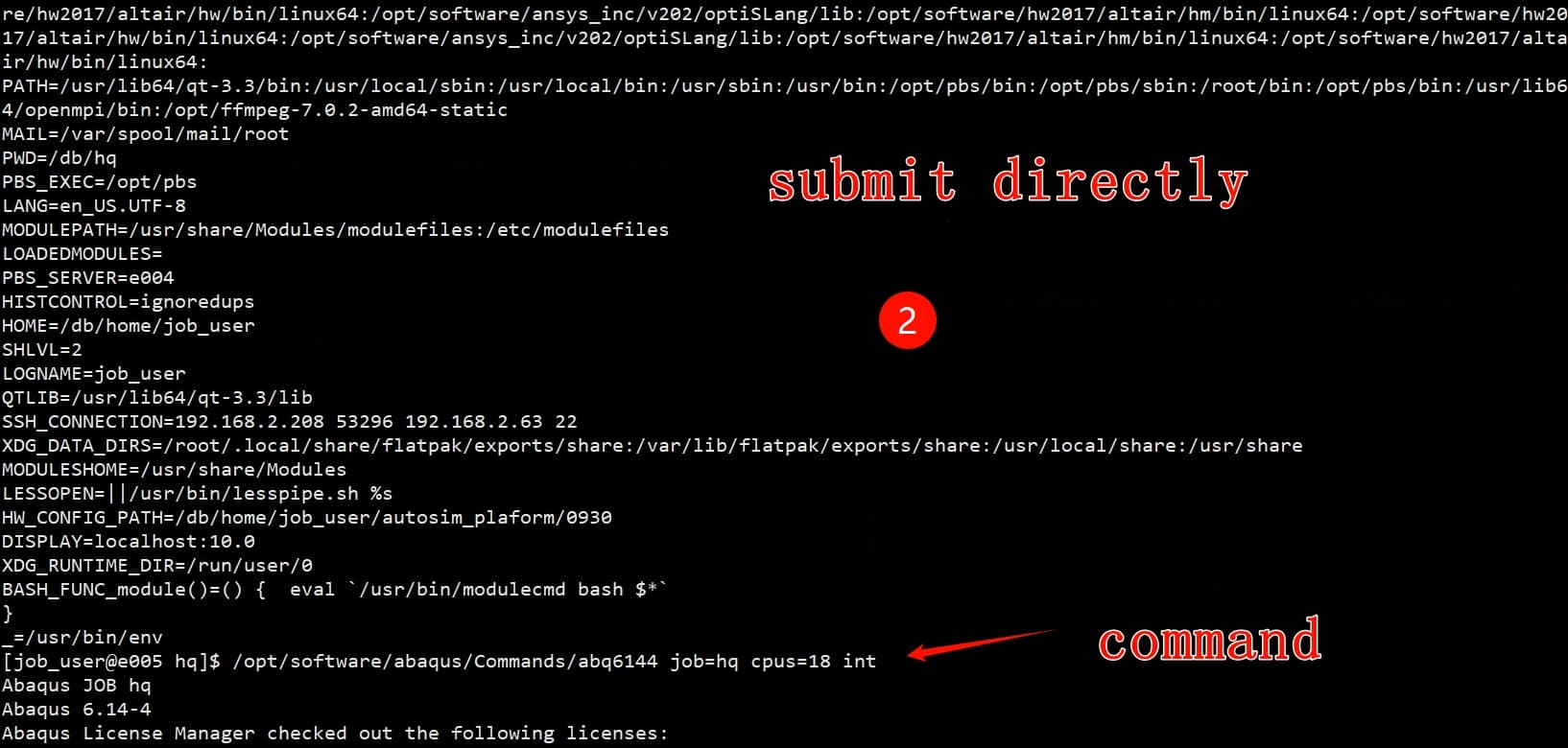






Thank you @wakaka for sharing the details.
create the below script in the /db/hq-throughpbs folder and submit the job
Plesae make relevant changes with the input file.
#PBS -N hq
#PBS -q workq
#PBS -V
#PBS -l select=1:ncpus=18
#PBS -o /db/hq-throughpbs/std.out
#PBS -e /db/hq-throughpbs/std.err
cd $PBS_O_WORKDIR
env
ls -ltr
/opt/software/abaqus/Commands/abq6144 job=hq input=hq.inp cpus=18 int
I submited the job after changed the script, but the completion time didn’t improve. The details are as follows:






Could you please try interactive console job and run the batch command line and check whether it runs quicker
qsub -V -l select=1:ncpus=18 -I -X <press enter>
computenode$: cd /db/hq-throughpbs
computenode$:/opt/software/abaqus/Commands/abq6144 job=hq cpus=18 int
My machine doesn’t support this way, but I found that the problem may be caused by shared memory pool(it’s jobs’s workdir), I calculated jobs in it. Now I want to copy jobs out to local machine from pool, after calculating, copy all results into pool, then delete results in local machine. Can any pbs comand achieve it?
Thank you very much for help.
Please check these attributes
#PBS -W sandbox=PRIVATE
#PBS –W stagein = <execution_path>@:<storage_path>
#PBS –W stageout = <execution_path>@:<storage_path
Document: https://help.altair.com/2024.1.0/PBS%20Professional/PBS2024.1.pdf
Search for : sandbox, stageout , stagein
I don’t know if I have the wrong format, but I can’t get the desired result. I set $jobdir_root in mom_priv/config of MoM, but after submitting the job, the jobdir is still not changed, and it is still in the home directory.


The jobdir would be used when you set -W sandbox=PRIVATE, please find the protocol below
Note: $jobdir_root /software/tmp set on the computenode1
[pbsdata@pbsserver ~]$ qsub -W sandbox=PRIVATE -I
qsub: waiting for job 6682.pbsserver to start
qsub: job 6682.pbsserver ready
cd /software/tmp/pbs.6682.pbsserver.x8z
[pbsdata@computenode1 ~]$ cd /software/tmp/pbs.6682.pbsserver.x8z
[pbsdata@computenode1 pbs.6682.pbsserver.x8z]$ echo $PBS_O_WORKDIR
/home/pbsdata
[pbsdata@computenode1 pbs.6682.pbsserver.x8z]$ pwd
/software/tmp/pbs.6682.pbsserver.x8z
[pbsdata@computenode1 pbs.6682.pbsserver.x8z]$ echo $PBS_JOBDIR
/software/tmp/pbs.6682.pbsserver.x8z
[pbsdata@computenode1 pbs.6682.pbsserver.x8z]$ exit
logout
qsub: job 6682.pbsserver completed
[pbsdata@pbsserver ~]$ qsub -I
qsub: waiting for job 6683.pbsserver to start
qsub: job 6683.pbsserver ready
[pbsdata@computenode1 ~]$ echo $PBS_JOBDIR
/home/pbsdata
[pbsdata@computenode1 ~]$ echo $PBS_O_WORKDIR
/home/pbsdata
[pbsdata@computenode1 ~]$ pwd
/home/pbsdata
[pbsdata@computenode1 ~]$ exit
logout
qsub: job 6683.pbsserver completed
Sample:
#!/bin/bash
#PBS -N samplejob
#PBS -l select=1:ncpus=1:mem=1gb
#PBS -W sandbox=PRIVATE
#copy the input.txt file from headnode from this location /home/pbsdata/inputlocation to private sandbox in the $jobdir_root location it is set or it will beh $HOME directory of the user. use comma separator to add multiple files
#PBS -W stagein=input.txt@headnode:/home/pbsdata/inputlocation/input.txt
#copy all the results file to headnode at this location /home/pbsdata/outputlocation/
#PBS -W stageout=*@headnode:/home/pbsdata/outputlocation```Thanks sincerely, my friend. It has worked.
Another question:
I used the form to define output file path and error file path, but it’s not right, I can’t qsub the job.
How can I correct the script?

1 Like
Please correct your stage in
#PBS -W stagein=simple.dat@e004:/nas-share/data/simple.dat
stdout and stderr
remove #PBS -k oed
#PBS -o e004:/path/to/standardout/
#PBS -e e004:/path/tostandarderror/
Thank you for your correction, adarsh. One more thing, when sanbox=PRIVATE, how do I set up multi-node distributed computing? Do I still need to configure NFS?
Thank you @wakaka
- shared storage ( common across all the compute nodes - NFS )
- local storage cross-mounted across all the nodes (NFS)
Yes